日志交互 web版
开发环境
- Ubuntu14.04 LTS + 其自带终端
- SublimeText2 (ST2)
- Python 2.7.10
- Firefox 41.0.2 for Ubuntu
Goal
- 完成极简交互式笔记的WEB版
- 通过网页访问系统
- 每次运行时合理的打印出过往的所有笔记
- 一次接收输入一行笔记
- 在服务端保存为文件
- 兼容Net版的,CLI可以进行交互
- 通过网页访问系统
准备
- networks 和 internet 和 port
- net 本地(共用一个cable)多台计算机 可以组成一个局域网络(打CS就可以使用局域网)(Local Area Network) 这些计算机之间的访问 需要通过MAC地址了
- Internet web 就是多个局域网 Network 组成的大的互联网 (打CS时 你需要连上互联网 才能与其他 network 中的 计算机用户 对战) 互联网中不同network中计算机的通信 恩 需要 Internet Protocol (IP) address 再通过 router 和 MAC 地址 进行通讯了
- port 端口 物理端口的话如插usb的那个口 这里的port是 两个机子之间通信过程 通过port来定义
- 具体参考
- 使用web frame work Bottle 0.12 来看看 Bottle的介绍 bottle是小而全的一个框架 精简而实用 恩 Pythonic
Bottle is a fast, simple and lightweight WSGI micro web-framework for Python. It is distributed as a single file module and has no dependencies other than the Python Standard Library
- 安装Bottle
- 你可以直接下载bottle.py 到自己的项目文件夹中
- 或者 你也可以 安装
- sudo pip install bottle
- 为什么要用框架
- web的开发 像建造楼房 打好外部的框架结构 再在此基础上 建造 就容易多了
- 有 web framework 恩 web的建造 也是容易的
熟悉
- 你可以走一遍 Tutorial: Todo-List Application
- 恩 建议先将代码自己码好 然后 运行理解
- 恩 以亲自码码为容 以复制粘帖为耻
建立一个简单的网页访问 webserver.py 代码如下
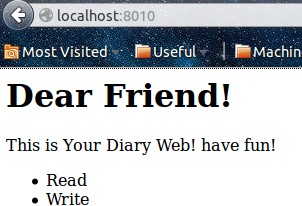
from bottle import * @route('/') # here you can type http://localhost:8010 to see hello welcome @route('/hello') def hello(): return """ # 返回的是html语法 恩 这样网页前端访问 有个基本的样子么 <body> <h1>Dear Friend!</h1> <p>This is Your Diary Web! have fun!</p> <ul> <li>Read</li> <li>Write</li> </ul> </body> """ run(host='localhost', port=8010, debug=True, reloader=1)- ST2中运行 恩 怎么运行 参考这篇SubPy
- 打开Firefox(你也可以用其他浏览器)键入 http://localhost:8010/ 就可以直接访你所建立的网页了
- 效果:
理解
- from bottle import * 导入模块 这样你才可以使用 bottle 的命令嘛
- route() 恩 这个 decorator 是为你的网页开路的 上网总得有个路径吧 恩 route() 来为你开路
The route() decorator binds a piece of code to an URL path.
- 你可以直接使用 @route('/hello') 这样的话你就需要键入 http://localhost:8010/hello 来访问网页
- 在前面 添加 @route('/') 那么直接键入 http://localhost:8010/ 就可以访问上面网页了
- 可以这么理解 恩 @route('/') 为 @route('/hello') 开好路了 直接 http://localhost:8010/ 就可以到达 http://localhost:8010/hello 内容
- 函数 恩 你有没有看到 @route() 后面都紧跟(或绑定bind)着一个定义的函数? 这里定义了 def hello() 这样 @route() 开好路 hello() 函数调用了
- hello() 函数直接返回的是 html 的内容 恩 这样 网页
- 什么是 html?恩 看这里 html 简单来说 就是建立网页的
- 恩 因为 hello() 函数返回的是 html 代码内容 所以打开 http://localhost:8010/ 链接 就直接建立了一个web网页
- return 要返回 html代码 这样就可以建立网页嘛
- run() 跑起来 才能 进行网页访问呢
- host 与 port 主机信息 port 端口信息
- debug = True 在开发的时候 你可以使用 如果运行出错 会显示错误内容 方便你debug 也可以直接写一行 debug(True) 开发完之后 记得取消哦
- reloader = 1 确认重新加载 恩 这样 你只要修改代码内容保存后 会直接自动加载
Dive In
在 webserver.py 中添加代码
import sqlite3
...
@route('/new', method='GET')
def new_item():
if request.GET.get('save','').strip():
new = request.GET.get('task', '').strip()
conn = sqlite3.connect('todo.db')
c = conn.cursor()
c.execute("INSERT INTO todo (task,status) VALUES (?,?)", (new,1))
new_id = c.lastrowid
conn.commit()
c.close()
return '<p>The new task was inserted into the database, the ID is %s</p>' % new_id
else:
return template('new_task.tpl')
...
例外新建 template 模块 new_task.tpl 代码如下:(需保存在与webserver.py同一个项目目录中)
%#template for the form for a new task
<p>Add a new task to the ToDo list:</p>
<form action="/new" method="GET">
<input type="text" size="100" maxlength="100" name="task">
<input type="submit" name="save" value="save">
</form>
理解
- sqlite3 DB-API 2.0 interface for SQLite databases DB-API 接口
- new_item() 函数
- 数据库中的交互
- return template('new_task.tpl')
- 返回 template 使用的是 new_task.tpl 模块
- new_task.tpl 模块 代码是 html 格式的 说明 返回的是html网页
- 在执行过程 中 你会发现 首先执行的是 else 中的 return template

- 然后网页刷新 会执行 if 返回 return '
The new task was inserted into the database, the ID is %s
' % new_id 这个网页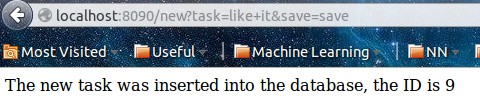
- 这里用到了 method=‘GET’
- if request.GET.get('save','') 如果 retrun template网页中 点击了 save 恩 这个if条件就成立 然后就执行 写入数据 并执行 if条件下的 那个return 返回网页
- 这说明 request.GET.get() 可以获取网页中的内容 主要是
- 其他关于数据库的内容 暂时不管
这样 你就可以使用上面的代码 来进行 极简交互式笔记的WEB版 开发了
极简交互式笔记的WEB版
代码 webserver.py
# coding=utf-8 from bottle import * import sys @route('/write', method="GET") def input_diary(): if request.GET.get('save','').strip(): # 之后执行这里 diary_words = request.GET.get('words','').strip() diary_name = 'Diary.log' # if not exist then creat diary_file = open(diary_name, 'a+') diary_file.write(diary_words + '\n') diary_file.close() return template('write_words.tpl', content=diary_words) # 再次返回网页 else: # 刚开始先执行这里的 diary_name = 'Diary.log' diary_file = open(diary_name, 'r') diary_content = diary_file.read() diary_file.close() return template('write_words.tpl', content=diary_content) if __name__ == '__main__': run(host='localhost', port=8010, debug=True, reloader=1) # switched debug off for publich applocationswrite_words.tpl 代码 :这个
<p>Write new words into your diary.log:</p> <form action="/write" method="GET"> <input type="text" size="100" maxlength="100" name="words" autofocus> <input type="submit" name="save" value="save"> </form> <p> Here is your diary content! Darling!</p> <textarea rows="30" cols="100">{{ content }}</textarea>firefox中键入:http://localhost:8010/write 就可以访问 web 了
效果:
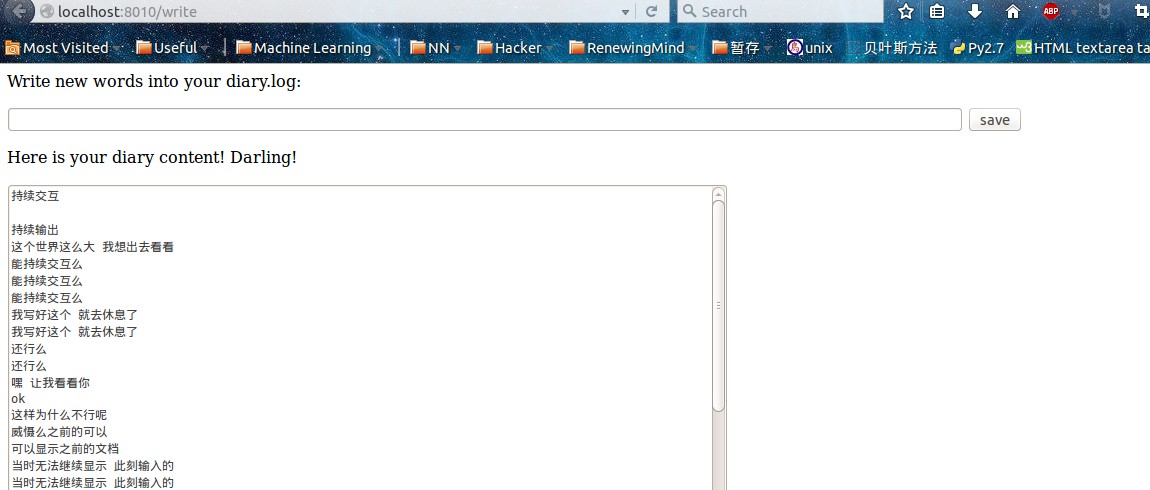
- 刚开始打印历史笔记
- 然后输入笔记内容 打印上一次输入笔记内容 非全部历史内容
走的弯路
刚开始的时候 想着 在write中 input_diary() 来一个while循环 使得可以持续输入恩 如
def input_diary():
done =True
while done == True:
if request.GET.get('save','').strip():
diary_words = request.GET.get('words','').strip()
if diary_words == 'q':
sys.exit()
else:
diary_name = 'Diary.log' # if not exist then creat
diary_file = open(diary_name, 'a+')
diary_file.write(diary_words + '\n') # write words your input
diary_file.close()
else:
return template('write_words.tpl')
结果就是 悲惨地发现 在text输入框中 输入一次 Diary.log 日志文件 一直在写入 立马关闭停止 然后Diary.log 文件很大 CLI 命令行 rm 都无法消除 然后 直接把整个文件夹删了 才没有该文件了
你会发现 自然而然地想到 循环来输入 然后 在这里 行不通 走不通之后 你一直刷行 write 网页 然后发现 只要在 if 条件下 再添加 return template不就行了 么
恩 只是上面的 只能在textarea中显示 你上一次的输入 没法显示 所有的历史记录
尝试解决:
在if下添加 diary_content 内容 然后 使用template输出
diary_content="" if request.GET.get('save','').strip(): diary_words = request.GET.get('words','').strip() diary_name = 'Diary.log' # if not exist then creat diary_file = open(diary_name, 'a+') diary_file.write(diary_words + '\n') diary_content += diary_words diary_file.close() return template('write_words.tpl', content=diary_content) # 再次返回网页- 结果是 还是只能打印上一次的输入笔记
- 分析 恩 看来 diary_content 还只是局部变量 重新刷了网页之后 还是空了
再次解决:
- 重新打开文件读取 再输入好了
恩 修改代码:
if request.GET.get('save','').strip(): diary_words = request.GET.get('words','').strip() diary_name = 'Diary.log' # if not exist then creat diary_file = open(diary_name, 'a+') diary_file.write(diary_words + '\n') # write words your diary_file.close() diary_file = open(diary_name, 'r') diary_content = diary_file.read() diary_file.close() return template('write_words.tpl', content=diary_content)
这样就解决了历史输出 虽然看起来 不精简 但也算是解决问题了 GO 哈利路亚
总
- web版笔记交互 开发只需要那么几步
- route 开路
- Request data
- 模板 template 使用 html 来建立网页
- 不要纠结小细节 恩 Go 哈利路亚
CLI 交互
- 理解
- 网页已经打开 大妈演示的时候是 lynx localhost:port 的 相当于已经打开了浏览器访问
- 然后用命令行CLI进行 交互 python CLI.py
- 恩 所以 这里 你只要再建立一个 CLI.py 就可以
- 恩 公开课的时候 大妈演示了 curl 基础使用
- 这里想必用curl
- go check curl doc 锁定 post(http) 功能 和 curl -G
POST (HTTP) It's easy to post data using curl. This is done using the -d option. The post data must be urlencoded.
curl -G localhost:8010 获取了网页的内容
在 终端上可以直接使用 但是用python 脚本 如何使用 尝试了 直接
content = curl -G localhost:8010 是不行的 语法错误 恩 说明 我还没有导入相关模块
那么 使用什么 模块呢? search Python code like curl go to pycurl 替代使用 pycurl
linux下 install pycurl 终于
sudo apt-get install python-pycurl
按照网站:
pip install pycurl 粗错了
sudo apt-get install pycurl 也出错的
下载压缩吧下来 python setup.py 也同样出错。。。
晕呀晕呀
简单执行 CLI.py
#! /usr/bin/env python
# -*- coding: utf-8 -*-
import pycurl
from StringIO import StringIO
import re
buffer = StringIO()
c = pycurl.Curl()
c.setopt(c.URL, 'http://localhost:8010/')
c.setopt(c.WRITEDATA, buffer)
c.perform()
c.close()
html_doc = buffer.getvalue()
print (html_doc)
得到:html
 。。。01
。。。01
再次理解
- pycurl可以将url中html中内容抓取下来
- 再要从抓取的html内容中获取 日志内容 (解析HTML)
- 写的话 就是将 input post 到 html 的textarea 中
解析HLML
添加代码:
from bs4 import BeautifulSoup
...
soup = BeautifulSoup(html_doc, 'html.parser')
print (soup.get_text())
恩这样得到了所有text内容

但是 你只想要 textarea中的内容 怎么办 修改为:
soup = BeautifulSoup(html_doc, 'html.parser')
soup_textarea = soup.find_all("textarea") # 这是list 类型的
print (soup_textarea)
恩 可以得到 textarea 中的所有内容 如下:
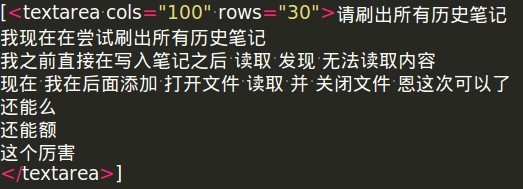
在此抓取 text 就ok 了吧 get_text 但是 soup_textarea 是list 类型的 你先要提取str 恩 哈利路亚 尝试提取str之后 就不知道该怎么进行了
soup_textarea = soup.find_all("textarea")
soup_textarea_str = str(soup_textarea).strip('[]') # convert list to string
再次尝试:
soup = BeautifulSoup(html_doc, 'html.parser')
soup_textarea = soup.textarea # TYPE is list
textarea_contents_str = str(soup_textarea.contents).strip('[]')
print textarea_contents_str
这次遇到了 编码问题 print的结果是这样的:

结果输出的 unicode 对象了 查看 textarea_contents_str 的type 是 str 呀 编码头疼 先放一边 soup_textarea.content 有问题
尝试解决:
soup = BeautifulSoup(html_doc, 'html.parser') # bs4的格式
soup_textarea = soup.textarea # TYPE is list
textarea_contents_str = soup_textarea.contents[0] # 这样的 类型<class 'bs4.element.NavigableString'>
print textarea_contents_str
这下正常输出了
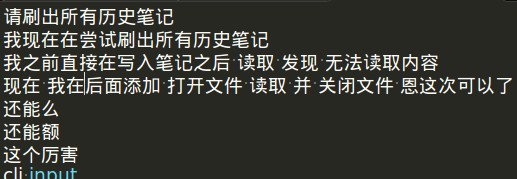
持续CLI写入
- raw_input 输入
- 将输入的内容写入到网站 并返回CLI 这个是关键 如何进行呢?
尝试 1 继续使用pycurl
还是使用pycurl:继续添加代码:
c = pycurl.Curl()
c.setopt(c.URL, 'http://localhost:8010/')
post_data = {'field': 'message'}
postfields = urlencode(post_data)
c.setopt(c.POSTFIELDS, postfields)
c.perform()
c.close()
结果失败:
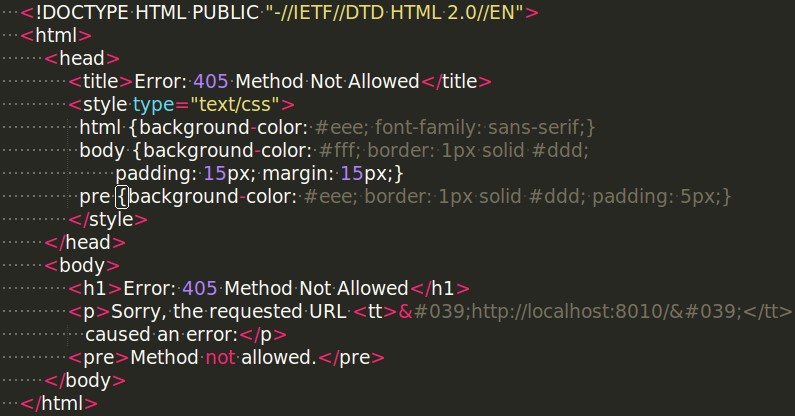
检索 不到 然后 转 Requests 库了 Requests
尝试2 使用Requests
install Requests
sudo apt-get install python-requests
没事查看模块版本 python下
>>> import requests
>>> print (requests.__version__)
2.2.1
修改CLI.py 为:
import requests
from bs4 import BeautifulSoup
import sys
html_doc = requests.get('http://localhost:8010/') # html_doc.text is the content of html
soup = BeautifulSoup(html_doc.text, 'html.parser')
soup_textarea = soup.textarea # TYPE is list
textarea_contents_str = soup_textarea.contents[0]
print textarea_contents_str
恩 简洁了些
post data: http://docs.python-requests.org/en/latest/user/quickstart/#more-complicated-post-requests
如何将 input post 到 text中内?
postdata = {'words': 'write?'} # words 为html 中的 text name
r = requests.post('http://localhost:8010/write', data = postdata)
print r.url
print r.text
出现与使用pycurl一样的 问题
恩 是 html 格式的问题 OK 修改 write_words.tpl 正规一点:
<!DOCTYPE >
<html>
<body>
<h1>Write new words into your diary.log:</h1>
<form action="/write" method="get">
<input type="text" size="100" maxlength="100" name="words" autofocus>
<input type="submit" name="save" value="save">
</form>
<h1> Darling!Here is your diary content!</h1>
<textarea rows="30" cols="100">{{ content }}</textarea>
</body>
</html>
恩 好看一点是没有用的 在服务端 响应 哈利路亚
"GET /write?words=get+and+post&save=save HTTP/1.1"
修改:
postdata = {'words': 'write?', ‘save’: 'save'}
还是不行 method 行不通
Method not allowed. # 去查看 method
那倒是
<form action="/write" method="get">
中 method是 get 我使用我使用 request的post 行么?恩 换回 get尝试 passing-parameters-in-urls
postdata = {'words': 'write', 'save': 'save'}
r = requests.get('http://localhost:8010/write', params = postdata)
print (r.url)
恩 这回可以了 打印的 url 为 http://localhost:8010/write?save=save&words=write 和网页端输入后一样
整合一下 持续交互 看结果 CLI.py
#! /usr/bin/env python
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import sys
def help():
""" # This is help doc:
1. Quit Please Type : exit /q/quit/Q
2. See Help Document Type: help/H/h/?
3. See Diary Histroy Type: hist
Let's Start. GO"""
def hist_logs():
html_doc = requests.get('http://localhost:8010/') # html_doc.text is the content of html
soup = BeautifulSoup(html_doc.text, 'html.parser') # html
soup_textarea = soup.textarea # TYPE is list
textarea_contents_str = soup_textarea.contents[0]
print textarea_contents_str
def input_logs(yourwords):
data = {'words': yourwords, 'save': 'save'} # two input in write_words.tpl so you must add name='save' item
requests.get('http://localhost:8010/write', params = data)
def main():
while True:
yourwords = raw_input('Type your words--->$')
if yourwords in {'exit', 'q', 'quit','Q'}:
sys.exit()
elif yourwords in {'help', 'H','h','?'}:
print help.__doc__
elif yourwords == 'hist':
hist_logs()
else:
input_logs(yourwords) # write new diarys or logs
if __name__ == '__main__':
main()
效果:(首先请运行 python webserver.py)
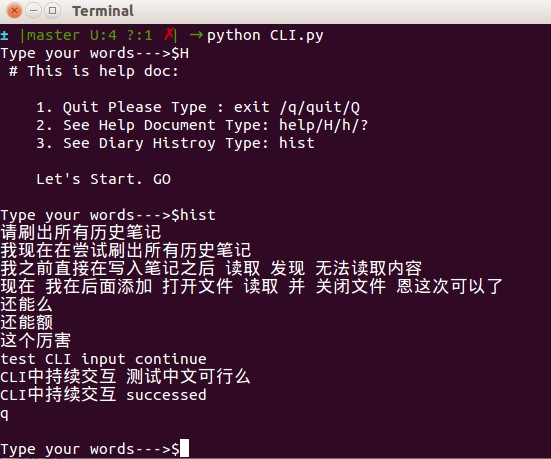
requests 可以解决了 那么 pycurl 类似 不过得用其GET 部分 恩 哈利路亚
继续迭代
- [x] CLI可以交互
- [] 美化网页 使用 bootstrap
- [] 数据库使用
总
- 坑终于填好了
- 没有最小代价解决问题 总是自己在琢磨 少了搜索 搜索也搜索不到 姿势不对么 不是
代码:
星期一, 09. 十一月 2015 01:07 AM 星期一, 09. 十一月 2015 10:24下午